
Regressão linear - Linear regression
| Parte de uma série sobre |
| Análise de regressão |
|---|
| Modelos |
| Estimativa |
| Fundo |
Em estatística , a regressão linear é uma abordagem linear para modelar a relação entre uma resposta escalar e uma ou mais variáveis explicativas (também conhecidas como variáveis dependentes e independentes ). O caso de uma variável explicativa é chamado de regressão linear simples ; para mais de um, o processo é chamado de regressão linear múltipla . Esse termo é diferente da regressão linear multivariada , em que várias variáveis dependentes correlacionadas são previstas, em vez de uma única variável escalar.
Na regressão linear, os relacionamentos são modelados usando funções de preditor linear cujos parâmetros de modelo desconhecidos são estimados a partir dos dados . Esses modelos são chamados de modelos lineares . Mais comumente, a média condicional da resposta, dados os valores das variáveis explicativas (ou preditores), é considerada uma função afim desses valores; menos comumente, a mediana condicional ou algum outro quantil é usado. Como todas as formas de análise de regressão , a regressão linear enfoca a distribuição de probabilidade condicional da resposta dados os valores dos preditores, em vez da distribuição de probabilidade conjunta de todas essas variáveis, que é o domínio da análise multivariada .
A regressão linear foi o primeiro tipo de análise de regressão a ser estudado rigorosamente e amplamente usado em aplicações práticas. Isso ocorre porque os modelos que dependem linearmente de seus parâmetros desconhecidos são mais fáceis de ajustar do que os modelos não linearmente relacionados aos seus parâmetros e porque as propriedades estatísticas dos estimadores resultantes são mais fáceis de determinar.
A regressão linear tem muitos usos práticos. A maioria dos aplicativos se enquadra em uma das seguintes duas categorias amplas:
- Se o objetivo for predição , previsão ou redução de erro, a regressão linear pode ser usada para ajustar um modelo preditivo a um conjunto de dados observado de valores da resposta e variáveis explicativas. Depois de desenvolver tal modelo, se valores adicionais das variáveis explicativas forem coletados sem um valor de resposta de acompanhamento, o modelo ajustado pode ser usado para fazer uma previsão da resposta.
- Se o objetivo é explicar a variação na variável de resposta que pode ser atribuída à variação nas variáveis explicativas, a análise de regressão linear pode ser aplicada para quantificar a força da relação entre a resposta e as variáveis explicativas e, em particular, para determinar se alguns as variáveis explicativas podem não ter nenhuma relação linear com a resposta ou para identificar quais subconjuntos de variáveis explicativas podem conter informações redundantes sobre a resposta.
Modelos de regressão linear são frequentemente ajustados usando a abordagem de mínimos quadrados , mas também podem ser ajustados de outras maneiras, como minimizando a "falta de ajuste" em alguma outra norma (como com regressão de desvios mínimos absolutos ), ou minimizando uma penalização versão da função de custo de mínimos quadrados como na regressão de crista ( penalidade da norma L 2 ) e laço ( penalidade da norma L 1 ). Por outro lado, a abordagem dos mínimos quadrados pode ser usada para ajustar modelos que não são modelos lineares. Assim, embora os termos "mínimos quadrados" e "modelo linear" estejam intimamente ligados, eles não são sinônimos.
Formulação

Dado um conjunto de dados de n unidades estatísticas , um modelo de regressão linear assume que a relação entre a variável dependente y e o p- vetor dos regressores x é linear . Essa relação é modelada por meio de um termo de perturbação ou variável de erro ε - uma variável aleatória não observada que adiciona "ruído" à relação linear entre a variável dependente e os regressores. Assim, o modelo assume a forma


onde T denota a transposta , de modo que x i T β é o produto interno entre os vetores x i e β .
Muitas vezes, essas n equações são empilhadas e escritas em notação de matriz como

Onde



Notação e terminologia
- é um vetor de valores observados da variável denominada regressando , variável endógena , variável de resposta , variável medida , variável de critério ou variável dependente . Às vezes, essa variável também é conhecida como variável prevista , mas não deve ser confundida com os valores previstos , que são denotados . A decisão sobre qual variável em um conjunto de dados é modelada como a variável dependente e quais são modeladas como as variáveis independentes pode ser baseada na presunção de que o valor de uma das variáveis é causado por, ou diretamente influenciado por outras variáveis. Alternativamente, pode haver uma razão operacional para modelar uma das variáveis em termos das outras, caso em que não há necessidade de presunção de causalidade.
-
pode ser visto como uma matriz de vetores linha ou de vetores coluna n- dimensionais , que são conhecidos como regressores , variáveis exógenas , variáveis explicativas , covariáveis , variáveis de entrada , variáveis preditoras ou variáveis independentes (não deve ser confundido com o conceito de variáveis aleatórias independentes ). A matriz às vezes é chamada de matriz de design .
- Normalmente, uma constante é incluída como um dos regressores. Em particular, para . O elemento correspondente de
- Às vezes, um dos regressores pode ser uma função não linear de outro regressor ou dos dados, como na regressão polinomial e na regressão segmentada . O modelo permanece linear enquanto for linear no vetor de parâmetros β .
- Os valores x ij podem ser vistos como valores observados de variáveis aleatórias X j ou como valores fixos escolhidos antes de observar a variável dependente. Ambas as interpretações podem ser apropriadas em casos diferentes e geralmente levam aos mesmos procedimentos de estimativa; no entanto, abordagens diferentes para análise assintótica são usadas nessas duas situações.













Ajustar um modelo linear a um determinado conjunto de dados geralmente requer estimar os coeficientes de regressão de forma que o termo de erro seja minimizado. Por exemplo, é comum usar a soma dos erros quadráticos como uma medida de minimização.


Exemplo
Considere uma situação em que uma pequena bola é lançada no ar e então medimos sua altura de subida h i em vários momentos no tempo t i . A física nos diz que, ignorando o arrasto, a relação pode ser modelada como

onde β 1 determina a velocidade inicial da bola, β 2 é proporcional à gravidade padrão e ε i é devido a erros de medição. A regressão linear pode ser usada para estimar os valores de β 1 e β 2 a partir dos dados medidos. Este modelo não é linear na variável tempo, mas é linear nos parâmetros β 1 e β 2 ; se tomarmos regressores x i = ( x i 1 , x i 2 ) = ( t i , t i 2 ), o modelo assume a forma padrão

Premissas
Os modelos de regressão linear padrão com técnicas de estimativa padrão fazem uma série de suposições sobre as variáveis preditoras, as variáveis de resposta e sua relação. Inúmeras extensões foram desenvolvidas para permitir que cada uma dessas suposições seja relaxada (ou seja, reduzida a uma forma mais fraca) e, em alguns casos, totalmente eliminada. Geralmente essas extensões tornam o procedimento de estimativa mais complexo e demorado, e também podem exigir mais dados para produzir um modelo igualmente preciso.

A seguir estão as principais suposições feitas por modelos de regressão linear padrão com técnicas de estimativa padrão (por exemplo, mínimos quadrados ordinários ):
- Exogeneidade fraca . Isso significa essencialmente que as variáveis preditoras x podem ser tratadas como valores fixos, em vez de variáveis aleatórias . Isso significa, por exemplo, que as variáveis preditoras são consideradas livres de erros, ou seja, não contaminadas com erros de medição. Embora essa suposição não seja realista em muitos ambientes, descartá-la leva a modelos de erros em variáveis significativamente mais difíceis .
- Linearidade . Isso significa que a média da variável de resposta é uma combinação linear dos parâmetros (coeficientes de regressão) e das variáveis preditoras. Observe que essa suposição é muito menos restritiva do que pode parecer à primeira vista. Como as variáveis preditoras são tratadas como valores fixos (veja acima), a linearidade é realmente apenas uma restrição aos parâmetros. As próprias variáveis de previsão podem ser transformadas arbitrariamente e, de fato, várias cópias da mesma variável de previsão subjacente podem ser adicionadas, cada uma transformada de maneira diferente. Essa técnica é usada, por exemplo, em regressão polinomial , que usa regressão linear para ajustar a variável de resposta como uma função polinomial arbitrária (até uma determinada classificação) de uma variável preditora. Com tanta flexibilidade, modelos como a regressão polinomial geralmente têm "muito poder", pois tendem a super ajustar os dados. Como resultado, algum tipo de regularização deve ser normalmente usado para evitar que soluções irracionais saiam do processo de estimativa. Exemplos comuns são a regressão do cume e a regressão do laço . A regressão linear bayesiana também pode ser usada, que por sua natureza é mais ou menos imune ao problema de overfitting. (Na verdade, a regressão crista e a regressão laço podem ser vistas como casos especiais de regressão linear bayesiana, com tipos particulares de distribuições anteriores colocadas nos coeficientes de regressão.)
- Variância constante (também conhecida como homocedasticidade ). Isso significa que a variância dos erros não depende dos valores das variáveis preditoras. Assim, a variabilidade das respostas para determinados valores fixos dos preditores é a mesma, independentemente de quão grandes ou pequenas as respostas são. Freqüentemente, esse não é o caso, pois uma variável cuja média é grande normalmente terá uma variância maior do que uma cuja média seja pequena. Por exemplo, uma pessoa cuja renda prevista seja de $ 100.000 pode facilmente ter uma renda real de $ 80.000 ou $ 120.000, ou seja, um desvio padrão de cerca de $ 20.000, enquanto outra pessoa com uma renda prevista de $ 10.000 provavelmente não terá o mesmo desvio padrão de $ 20.000 , uma vez que isso implicaria que sua renda real poderia variar entre - $ 10.000 e $ 30.000. (Na verdade, como isso mostra, em muitos casos - frequentemente os mesmos casos em que a suposição de erros normalmente distribuídos falha - a variância ou desvio padrão deve ser previsto para ser proporcional à média, em vez de constante.) A ausência de homocedasticidade é chamado heterocedasticidade . A fim de verificar esta suposição, um gráfico de resíduos versus valores previstos (ou os valores de cada preditor individual) pode ser examinado para um "efeito de leque" (ou seja, aumentando ou diminuindo a propagação vertical conforme alguém se move da esquerda para a direita no gráfico) . Um gráfico dos resíduos absolutos ou quadrados versus os valores previstos (ou cada preditor) também pode ser examinado para uma tendência ou curvatura. Testes formais também podem ser usados; veja Heteroscedasticidade . A presença de heterocedasticidade resultará na utilização de uma estimativa "média" geral da variância, em vez de uma que leve em consideração a verdadeira estrutura da variância. Isso leva a estimativas de parâmetros menos precisas (mas no caso de mínimos quadrados ordinários , não enviesados) e erros padrão enviesados, resultando em testes enganosos e estimativas de intervalo. O erro quadrático médio para o modelo também estará errado. Várias técnicas de estimativa, incluindo mínimos quadrados ponderados e o uso de erros padrão consistentes com heterocedasticidade, podem lidar com a heterocedasticidade de uma maneira bastante geral. As técnicas de regressão linear bayesiana também podem ser usadas quando a variância é assumida como uma função da média. Também é possível, em alguns casos, corrigir o problema aplicando uma transformação à variável de resposta (por exemplo, ajustando o logaritmo da variável de resposta usando um modelo de regressão linear, o que implica que a própria variável de resposta tem uma distribuição log-normal em vez de uma distribuição normal ).
-
Independência de erros . Isso pressupõe que os erros das variáveis de resposta não estão correlacionados entre si. (A independência estatística real é uma condição mais forte do que a mera falta de correlação e muitas vezes não é necessária, embora possa ser explorada se for conhecida.) Alguns métodos, como mínimos quadrados generalizados, são capazes de lidar com erros correlacionados, embora normalmente exijam significativamente mais dados, a menos que algum tipo de regularização seja usado para influenciar o modelo no sentido de assumir erros não correlacionados. A regressão linear bayesiana é uma maneira geral de lidar com esse problema.
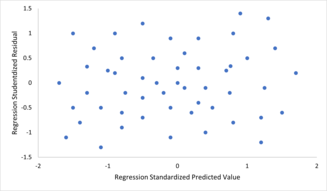 Para verificar se há violações das premissas de linearidade, variância constante e independência de erros em um modelo de regressão linear, os resíduos são normalmente plotados contra os valores previstos (ou cada um dos preditores individuais). Uma dispersão aparentemente aleatória de pontos sobre a linha média horizontal em 0 é ideal, mas não pode descartar certos tipos de violações, como autocorrelação nos erros ou sua correlação com uma ou mais covariáveis.
Para verificar se há violações das premissas de linearidade, variância constante e independência de erros em um modelo de regressão linear, os resíduos são normalmente plotados contra os valores previstos (ou cada um dos preditores individuais). Uma dispersão aparentemente aleatória de pontos sobre a linha média horizontal em 0 é ideal, mas não pode descartar certos tipos de violações, como autocorrelação nos erros ou sua correlação com uma ou mais covariáveis. - Falta de multicolinearidade perfeita nos preditores. Para métodos de estimativa de mínimos quadrados padrão , a matriz de design X deve ter classificação de coluna completa p ; caso contrário, a multicolinearidade perfeita existe nas variáveis preditoras, o que significa que existe uma relação linear entre duas ou mais variáveis preditoras. Isso pode ser causado pela duplicação acidental de uma variável nos dados, usando uma transformação linear de uma variável junto com a original (por exemplo, as mesmas medições de temperatura expressas em Fahrenheit e Celsius), ou incluindo uma combinação linear de múltiplas variáveis no modelo, como sua média. Também pode acontecer se houver poucos dados disponíveis em comparação com o número de parâmetros a serem estimados (por exemplo, menos pontos de dados do que coeficientes de regressão). Quase violações dessa suposição, onde os preditores são altamente, mas não perfeitamente correlacionados, podem reduzir a precisão das estimativas de parâmetro (consulte Fator de inflação de variância ). No caso de multicolinearidade perfeita, o vetor de parâmetros β será não identificável - não tem solução única. Nesse caso, apenas alguns dos parâmetros podem ser identificados (ou seja, seus valores só podem ser estimados dentro de algum subespaço linear de todo o espaço de parâmetros R p ). Veja regressão de mínimos quadrados parciais . Métodos para ajustar modelos lineares com multicolinearidade foram desenvolvidos, alguns dos quais requerem suposições adicionais, como "dispersão do efeito" - que uma grande fração dos efeitos é exatamente zero. Observe que os algoritmos iterados mais caros computacionalmente para estimativa de parâmetros, como aqueles usados em modelos lineares generalizados , não sofrem desse problema.

Além dessas suposições, várias outras propriedades estatísticas dos dados influenciam fortemente o desempenho de diferentes métodos de estimativa:
- A relação estatística entre os termos de erro e os regressores desempenha um papel importante em determinar se um procedimento de estimativa tem propriedades de amostragem desejáveis, como ser imparcial e consistente.
- O arranjo ou distribuição de probabilidade das variáveis preditoras x tem uma grande influência na precisão das estimativas de β . Amostragem e projeto de experimentos são subcampos altamente desenvolvidos da estatística que fornecem orientação para a coleta de dados de forma a atingir uma estimativa precisa de β .
Interpretação

Um modelo de regressão linear ajustado pode ser usado para identificar a relação entre uma única variável preditora x j e a variável de resposta y quando todas as outras variáveis preditoras no modelo são "mantidas fixas". Especificamente, a interpretação de β j é a mudança esperada em y para uma mudança de uma unidade em x j quando as outras covariáveis são mantidas fixas - isto é, o valor esperado da derivada parcial de y em relação a x j . Isso às vezes é chamado de efeito exclusivo de x j sobre y . Em contraste, o efeito marginal de x j em y pode ser avaliado usando um coeficiente de correlação ou modelo de regressão linear simples relacionando apenas x j a y ; esse efeito é a derivada total de y em relação a x j .
Deve-se tomar cuidado ao interpretar os resultados da regressão, pois alguns dos regressores podem não permitir mudanças marginais (como variáveis dummy ou o termo de interceptação), enquanto outros não podem ser mantidos fixos (lembre-se do exemplo da introdução: seria impossível para "manter t i fixo" e ao mesmo tempo alterar o valor de t i 2 ).
É possível que o efeito único seja quase zero, mesmo quando o efeito marginal é grande. Isso pode implicar que alguma outra covariável captura todas as informações em x j , de modo que, uma vez que a variável está no modelo, não há contribuição de x j para a variação em y . Por outro lado, o efeito único de x j pode ser grande, enquanto seu efeito marginal é quase zero. Isso aconteceria se as outras covariáveis explicassem uma grande parte da variação de y , mas explicam principalmente a variação de uma forma que é complementar ao que é capturado por x j . Nesse caso, a inclusão das outras variáveis no modelo reduz a parte da variabilidade de y que não está relacionada a x j , fortalecendo, assim, a relação aparente com x j .
O significado da expressão "mantido fixo" pode depender de como os valores das variáveis preditoras surgem. Se o experimentador define diretamente os valores das variáveis preditoras de acordo com um desenho de estudo, as comparações de interesse podem literalmente corresponder a comparações entre unidades cujas variáveis preditoras foram "mantidas fixas" pelo experimentador. Alternativamente, a expressão "mantido fixo" pode se referir a uma seleção que ocorre no contexto da análise de dados. Nesse caso, "mantemos uma variável fixa", restringindo nossa atenção aos subconjuntos de dados que possuem um valor comum para a variável preditora fornecida. Esta é a única interpretação de "mantido fixo" que pode ser usada em um estudo observacional.
A noção de um "efeito único" é atraente ao estudar um sistema complexo onde vários componentes inter-relacionados influenciam a variável de resposta. Em alguns casos, pode ser interpretado literalmente como o efeito causal de uma intervenção que está ligada ao valor de uma variável preditora. No entanto, foi argumentado que, em muitos casos, a análise de regressão múltipla falha em esclarecer as relações entre as variáveis preditoras e a variável de resposta quando os preditores estão correlacionados entre si e não são atribuídos de acordo com um desenho de estudo.
Extensões
Numerosas extensões de regressão linear foram desenvolvidas, o que permite que algumas ou todas as suposições subjacentes ao modelo básico sejam relaxadas.
Regressão linear simples e múltipla

O caso mais simples de uma única variável preditora escalar x e uma única variável de resposta escalar y é conhecido como regressão linear simples . A extensão para variáveis preditoras com valores múltiplos e / ou vetoriais (denotadas com um X maiúsculo ) é conhecida como regressão linear múltipla , também conhecida como regressão linear multivariada (não deve ser confundida com regressão linear multivariada ).
A regressão linear múltipla é uma generalização da regressão linear simples para o caso de mais de uma variável independente e um caso especial de modelos lineares gerais, restrito a uma variável dependente. O modelo básico para regressão linear múltipla é

para cada observação i = 1, ..., n .
Na fórmula acima, consideramos n observações de uma variável dependente ep variáveis independentes. Assim, Y i é a i ésima observação da variável dependente, X ij é a i ésima observação da j ésima variável independente, j = 1, 2, ..., p . Os valores β j representam parâmetros a serem estimados, e ε i é o i ésimo erro normal distribuído de forma independente e idêntica.
Na regressão linear multivariada mais geral, há uma equação da forma acima para cada uma das m > 1 variáveis dependentes que compartilham o mesmo conjunto de variáveis explicativas e, portanto, são estimadas simultaneamente entre si:

para todas as observações indexadas como i = 1, ..., n e para todas as variáveis dependentes indexadas como j = 1, ..., m .
Quase todos os modelos de regressão do mundo real envolvem vários preditores, e as descrições básicas da regressão linear são frequentemente formuladas em termos do modelo de regressão múltipla. Observe, entretanto, que, nesses casos, a variável de resposta y ainda é escalar. Outro termo, regressão linear multivariada , refere-se a casos em que y é um vetor, ou seja, o mesmo que regressão linear geral .
Modelos lineares gerais
O modelo linear geral considera a situação quando a variável de resposta não é um escalar (para cada observação), mas um vetor, y i . A linearidade condicional de ainda é assumida, com uma matriz B substituindo o vetor β do modelo de regressão linear clássico. Análogos multivariados de mínimos quadrados ordinários (OLS) e mínimos quadrados generalizados (GLS) foram desenvolvidos. Os "modelos lineares gerais" também são chamados de "modelos lineares multivariados". Eles não são iguais aos modelos lineares multivariáveis (também chamados de "modelos lineares múltiplos").

Modelos heterocedásticos
Vários modelos foram criados que permitem a heterocedasticidade , ou seja, os erros para diferentes variáveis de resposta podem ter variâncias diferentes . Por exemplo, mínimos quadrados ponderados é um método para estimar modelos de regressão linear quando as variáveis de resposta podem ter variâncias de erro diferentes, possivelmente com erros correlacionados. (Consulte também Mínimos quadrados lineares ponderados e Mínimos quadrados generalizados .) Erros padrão consistentes com heterocedasticidade é um método aprimorado para uso com erros não correlacionados, mas potencialmente heterocedásticos.
Modelos lineares generalizados
Modelos lineares generalizados (GLMs) são uma estrutura para modelar variáveis de resposta que são limitadas ou discretas. Isso é usado, por exemplo:
- ao modelar quantidades positivas (por exemplo, preços ou populações) que variam em grande escala - que são melhor descritas usando uma distribuição enviesada , como a distribuição log-normal ou distribuição de Poisson (embora GLMs não sejam usados para dados log-normal, em vez da resposta variável é simplesmente transformada usando a função logaritmo);
- ao modelar dados categóricos , como a escolha de um determinado candidato em uma eleição (que é melhor descrita usando uma distribuição de Bernoulli / distribuição binomial para escolhas binárias ou uma distribuição categórica / distribuição multinomial para escolhas de múltiplas vias), onde há uma número fixo de opções que não podem ser ordenadas de forma significativa;
- ao modelar dados ordinais , por exemplo, classificações em uma escala de 0 a 5, onde os diferentes resultados podem ser ordenados, mas onde a própria quantidade pode não ter qualquer significado absoluto (por exemplo, uma classificação de 4 pode não ser "duas vezes melhor" em qualquer objetivo sentido como uma classificação de 2, mas simplesmente indica que é melhor do que 2 ou 3, mas não tão bom quanto 5).
Modelos lineares generalizados para permitir uma arbitrária função de ligação , g , que se relaciona com a média da variável de resposta (s) para os preditores: . A função de ligação está frequentemente relacionada à distribuição da resposta e, em particular, normalmente tem o efeito de transformar entre o intervalo do preditor linear e o intervalo da variável de resposta.


Alguns exemplos comuns de GLMs são:
- Regressão de Poisson para dados de contagem.
- Regressão logística e regressão probit para dados binários.
- Regressão logística multinomial e regressão probit multinomial para dados categóricos.
- Logit ordenado e regressão probit ordenada para dados ordinais.
Modelos único índice permitir algum grau de não-linearidade na relação entre x e y , preservando ao mesmo tempo o papel central do preditor linear β ' x como no modelo de regressão linear clássico. Sob certas condições, a simples aplicação de OLS aos dados de um modelo de índice único estimará β de forma consistente até uma constante de proporcionalidade.
Modelos lineares hierárquicos
Modelos lineares hierárquicos (ou multinível ) organiza os dados dentro de uma hierarquia de regressões, por exemplo, onde A é regrediram em B , e B é regrediram em C . É frequentemente usado onde as variáveis de interesse têm uma estrutura hierárquica natural, como em estatísticas educacionais, onde os alunos estão aninhados nas salas de aula, as salas de aula estão aninhadas nas escolas e as escolas estão aninhadas em algum agrupamento administrativo, como um distrito escolar. A variável de resposta pode ser uma medida do desempenho do aluno, como uma pontuação de teste, e diferentes covariáveis seriam coletadas nos níveis de sala de aula, escola e distrito escolar.
Erros em variáveis
Os modelos de erros em variáveis (ou "modelos de erro de medição") estendem o modelo de regressão linear tradicional para permitir que as variáveis preditoras X sejam observadas com erro. Este erro faz com que os estimadores padrão de β sejam enviesados. Geralmente, a forma de viés é uma atenuação, o que significa que os efeitos são tendenciosos para zero.
Outros
- Na teoria de Dempster-Shafer , ou em uma função de crença linear em particular, um modelo de regressão linear pode ser representado como uma matriz parcialmente varrida, que pode ser combinada com matrizes semelhantes que representam observações e outras distribuições normais assumidas e equações de estado. A combinação de matrizes com ou sem varredura fornece um método alternativo para estimar modelos de regressão linear.
Métodos de estimativa
Um grande número de procedimentos foi desenvolvido para estimativa de parâmetros e inferência em regressão linear. Esses métodos diferem na simplicidade computacional de algoritmos, presença de uma solução de forma fechada, robustez em relação a distribuições de cauda pesada e suposições teóricas necessárias para validar propriedades estatísticas desejáveis, como consistência e eficiência assintótica .
Algumas das técnicas de estimativa mais comuns para regressão linear são resumidas abaixo.

Assumindo que a variável independente é e os parâmetros do modelo são , então a previsão do modelo seria
![{\ displaystyle {\ vec {x_ {i}}} = \ left [x_ {1} ^ {i}, x_ {2} ^ {i}, \ ldots, x_ {m} ^ {i} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/156ecace8a311d501c63ca49c73bba6efc915283)
![{\ displaystyle {\ vec {\ beta}} = \ left [\ beta _ {0}, \ beta _ {1}, \ ldots, \ beta _ {m} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/32434f0942d63c868f23d5af39442bb90783633b)
- .

Se for estendido para, então se tornaria um produto escalar do parâmetro e da variável independente, ou seja,

![{\ displaystyle {\ vec {x_ {i}}} = \ left [1, x_ {1} ^ {i}, x_ {2} ^ {i}, \ ldots, x_ {m} ^ {i} \ right ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f72fa7acd1682497c285884b0686d784d8b0eb15)

- .

Na configuração de mínimos quadrados, o parâmetro ideal é definido como tal que minimiza a soma da perda quadrada média:

Agora, colocando as variáveis independentes e dependentes em matrizes e , respectivamente, a função de perda pode ser reescrita como:


Como a perda é convexa, a solução ótima encontra-se no gradiente zero. O gradiente da função de perda é (usando a convenção de layout do Denominador ):

Definir o gradiente como zero produz o parâmetro ideal:

Nota: Para provar que o obtido é de fato o mínimo local, é preciso diferenciar mais uma vez para obter a matriz Hessiana e mostrar que ela é definida positiva. Isso é fornecido pelo teorema de Gauss-Markov .

Os métodos de mínimos quadrados lineares incluem principalmente:
- A estimativa de máxima verossimilhança pode ser realizada quando a distribuição dos termos de erro é conhecida por pertencer a uma certa família paramétrica ƒ θ de distribuições de probabilidade . Quando f θ é uma distribuição normal com média zeroe variância θ, a estimativa resultante é idêntica à estimativa OLS. As estimativas de GLS são estimativas de máxima verossimilhança quando ε segue uma distribuição normal multivariada com uma matriz de covariância conhecida.
- A regressão Ridge e outras formas de estimativa penalizada, como a regressão Lasso , introduzem deliberadamente o viés na estimativa de β a fim de reduzir a variabilidade da estimativa. As estimativas resultantes geralmente têm erro quadrático médio mais baixo doque as estimativas OLS, particularmente quando a multicolinearidade está presente ou quando o overfitting é um problema. Eles geralmente são usados quando o objetivo é prever o valor da variável de resposta y para os valores dos preditores x que ainda não foram observados. Esses métodos não são tão comumente usados quando o objetivo é a inferência, uma vez que é difícil explicar o viés.
- A regressão de menor desvio absoluto (LAD) é umatécnica de estimativa robusta , pois é menos sensível à presença de valores discrepantes do que OLS (mas é menos eficiente do que OLS quando nenhum valor discrepante está presente). É equivalente à estimativa de máxima verossimilhança sob ummodelo de distribuição de Laplace para ε .
- Estimativa adaptativa . Se assumirmos que os termos de erro são independentes dos regressores, então o estimador ótimo é o MLE de 2 etapas, onde a primeira etapa é usada para estimar não parametricamente a distribuição do termo de erro.

Outras técnicas de estimativa

- A regressão linear bayesiana aplica a estrutura da estatística bayesiana à regressão linear. (Consulte também regressão linear multivariada bayesiana .) Em particular, os coeficientes de regressão β são considerados variáveis aleatórias com uma distribuição anterior especificada. A distribuição anterior pode enviesar as soluções para os coeficientes de regressão, de forma semelhante (mas mais geral do que) regressão de cume ou regressão de laço . Além disso, o processo de estimativa bayesiana produz não uma estimativa pontual única para os "melhores" valores dos coeficientes de regressão, mas uma distribuição posterior inteira, descrevendo completamente a incerteza em torno da quantidade. Isso pode ser usado para estimar os "melhores" coeficientes usando a média, modo, mediana, qualquer quantil (ver regressão de quantil ) ou qualquer outra função da distribuição posterior.
- Regressão quantílica incide sobre os quantis condicionais de y dado X , em vez da média condicional de y dado X . A regressão quantílica linear modela um determinado quantil condicional, por exemplo a mediana condicional, como uma função linear β T x dos preditores.
- Modelos mistos são amplamente usados para analisar relacionamentos de regressão linear envolvendo dados dependentes quando as dependências têm uma estrutura conhecida. As aplicações comuns de modelos mistos incluem a análise de dados envolvendo medições repetidas, como dados longitudinais ou dados obtidos de amostragem por agrupamento. Eles geralmente são ajustados comomodelos paramétricos , usando máxima verossimilhança ou estimativa Bayesiana. No caso em que os erros são modelados comovariáveis aleatórias normais , há uma conexão estreita entre modelos mistos e mínimos quadrados generalizados. A estimativa de efeitos fixos é uma abordagem alternativa para analisar esse tipo de dados.
- A regressão de componente principal (PCR) é usada quando o número de variáveis preditoras é grande ou quando existem fortes correlações entre as variáveis preditoras. Este procedimento de dois estágios primeiro reduz as variáveis preditoras usando a análise de componente principal e, em seguida, usa as variáveis reduzidas em um ajuste de regressão OLS. Embora muitas vezes funcione bem na prática, não há razão teórica geral para que a função linear mais informativa das variáveis preditoras deva estar entre os componentes principais dominantes da distribuição multivariada das variáveis preditoras. A regressão de mínimos quadrados parciais é a extensão do método de PCR que não sofre da deficiência mencionada.
- A regressão de ângulo mínimo é um procedimento de estimativa para modelos de regressão linear que foi desenvolvido para lidar com vetores covariáveis de alta dimensão, potencialmente com mais covariáveis do que observações.
- O estimador de Theil-Sen é uma técnica de estimativa simples e robusta que escolhe a inclinação da linha de ajuste como a mediana das inclinações das linhas por meio de pares de pontos de amostra. Ele tem propriedades de eficiência estatística semelhantes à regressão linear simples, mas é muito menos sensível a outliers .
- Outras técnicas de estimação robustas, incluindo a abordagem da média aparada em α e estimadores L-, M-, S- e R foram introduzidos.
Formulários
A regressão linear é amplamente usada nas ciências biológicas, comportamentais e sociais para descrever possíveis relações entre variáveis. É uma das ferramentas mais importantes utilizadas nessas disciplinas.
Linha de tendência
Uma linha de tendência representa uma tendência, o movimento de longo prazo nos dados da série temporal depois que outros componentes foram contabilizados. Ele informa se um determinado conjunto de dados (por exemplo, PIB, preços do petróleo ou preços das ações) aumentou ou diminuiu ao longo do período. Uma linha de tendência poderia simplesmente ser desenhada a olho nu através de um conjunto de pontos de dados, mas mais apropriadamente sua posição e inclinação são calculadas usando técnicas estatísticas como regressão linear. As linhas de tendência normalmente são linhas retas, embora algumas variações usem polinômios de alto grau dependendo do grau de curvatura desejado na linha.
As linhas de tendência às vezes são usadas em análises de negócios para mostrar mudanças nos dados ao longo do tempo. Tem a vantagem de ser simples. As linhas de tendência costumam ser usadas para argumentar que uma ação ou evento específico (como um treinamento ou uma campanha publicitária) causou mudanças observadas em um determinado momento. Esta é uma técnica simples e não requer um grupo de controle, projeto experimental ou uma técnica de análise sofisticada. No entanto, ele sofre de uma falta de validade científica nos casos em que outras alterações potenciais podem afetar os dados.
Epidemiologia
As primeiras evidências relacionando o tabagismo à mortalidade e morbidade vieram de estudos observacionais que empregam análise de regressão. Para reduzir as correlações espúrias ao analisar dados observacionais, os pesquisadores geralmente incluem várias variáveis em seus modelos de regressão, além da variável de interesse primário. Por exemplo, em um modelo de regressão no qual o tabagismo é a variável independente de interesse primário e a variável dependente é a expectativa de vida medida em anos, os pesquisadores podem incluir educação e renda como variáveis independentes adicionais, para garantir que qualquer efeito observado do tabagismo na expectativa de vida seja não devido a esses outros fatores socioeconômicos . No entanto, nunca é possível incluir todas as variáveis de confusão possíveis em uma análise empírica. Por exemplo, um gene hipotético pode aumentar a mortalidade e também fazer com que as pessoas fumem mais. Por esse motivo, os ensaios clínicos randomizados geralmente são capazes de gerar evidências mais convincentes de relações causais do que as que podem ser obtidas por meio de análises de regressão de dados observacionais. Quando experimentos controlados não são viáveis, variantes de análise de regressão, como regressão de variáveis instrumentais, podem ser usadas para tentar estimar relações causais a partir de dados observacionais.
Finança
O modelo de precificação de ativos de capital usa regressão linear, bem como o conceito de beta para analisar e quantificar o risco sistemático de um investimento. Isso vem diretamente do coeficiente beta do modelo de regressão linear que relaciona o retorno do investimento ao retorno de todos os ativos de risco.
Economia
A regressão linear é a ferramenta empírica predominante em economia . Por exemplo, é usado para prever gastos de consumo , gastos de investimento fixo , investimento em estoque , compras de exportações de um país , gastos com importações , a demanda para manter ativos líquidos , demanda de trabalho e oferta de trabalho .
Ciência ambiental
A regressão linear encontra aplicação em uma ampla gama de aplicações da ciência ambiental. No Canadá, o Programa de Monitoramento de Efeitos Ambientais usa análises estatísticas sobre peixes e pesquisas bentônicas para medir os efeitos da fábrica de celulose ou efluentes de minas de metal no ecossistema aquático.
Aprendizado de máquina
A regressão linear desempenha um papel importante no subcampo da inteligência artificial conhecido como aprendizado de máquina . O algoritmo de regressão linear é um dos algoritmos de aprendizado de máquina supervisionado fundamentais devido à sua relativa simplicidade e propriedades bem conhecidas.
História
A regressão linear de mínimos quadrados, como meio de encontrar um bom ajuste linear bruto para um conjunto de pontos, foi realizada por Legendre (1805) e Gauss (1809) para a previsão do movimento planetário. Quetelet foi responsável por tornar o procedimento conhecido e por utilizá-lo extensivamente nas ciências sociais.
Veja também
- Análise de variação
- Decomposição Blinder-Oaxaca
- Modelo de regressão censurado
- Regressão transversal
- Ajuste de curva
- Métodos empíricos de Bayes
- Erros e residuais
- Soma de quadrados de falta de ajuste
- Encaixe de linha
- Classificador linear
- Equação linear
- Regressão logística
- Estimador M
- Splines de regressão adaptativa multivariada
- Regressão não linear
- Regressão não paramétrica
- Equações normais
- Regressão de perseguição de projeção
- Metodologia de modelagem de resposta
- Regressão linear segmentada
- Regressão Stepwise
- Quebra estrutural
- Máquina de vetor de suporte
- Modelo de regressão truncado
- Regressão de Deming
Referências
Citações
Fontes
- Cohen, J., Cohen P., West, SG, & Aiken, LS (2003). Análise de regressão / correlação múltipla aplicada para as ciências do comportamento . (2ª ed.) Hillsdale, NJ: Lawrence Erlbaum Associates
- Charles Darwin . A variação de animais e plantas sob domesticação . (1868) (o Capítulo XIII descreve o que se sabia sobre a reversão na época de Galton. Darwin usa o termo "reversão".)
- Draper, NR; Smith, H. (1998). Análise de regressão aplicada (3ª ed.). John Wiley. ISBN 978-0-471-17082-2.
- Francis Galton. "Regression Towards Mediocrity in Hereditary Stature", Journal of the Anthropological Institute , 15: 246-263 (1886). (Fax em: [1] )
- Robert S. Pindyck e Daniel L. Rubinfeld (1998, 4ª ed.). Modelos econométricos e previsões econômicas , cap. 1 (Introdução, incl. Apêndices sobre Σ operadores e derivação de est. De parâmetro) e Apêndice 4.3 (regressão múltipla em forma de matriz).
Leitura adicional
- Pedhazur, Elazar J (1982). Regressão múltipla em pesquisa comportamental: Explicação e previsão (2ª ed.). Nova York: Holt, Rinehart e Winston. ISBN 978-0-03-041760-3.
- Mathieu Rouaud, 2013: Probabilidade, Estatística e Estimação Capítulo 2: Regressão Linear, Regressão Linear com Barras de Erro e Regressão Não Linear.
- Laboratório Físico Nacional (1961). "Capítulo 1: Equações lineares e matrizes: métodos diretos". Métodos de computação modernos . Notes on Applied Science. 16 (2ª ed.). Escritório de artigos de papelaria de Sua Majestade .
links externos
- Regressão de mínimos quadrados , simulações PhET Interactive, University of Colorado at Boulder
- DIY Linear Fit